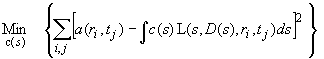
continuous distribution c(s) Lamm equation model
Model | continuous c(s) distribution
The c(s) distribution is a variant of the distribution of Lamm equation solutions:
A general introduction into the theory and practice of size-distribution analysis can be found here. A practical step-by-step tutorial for using this model is given here. The use of the c(s) analysis is also displayed in the example application of Sedfit, and theoretical and experimental considerations are reviewed here. Further information, and comparison with other models can be found (here) . See this presentation for the use of c(s) distributions in the analysis of rapidly reacting systems: c(s) based analysis of rapidly interacting systems.
By default, regularization of the distribution by the maximum entropy method is used.
It should be noted that this model is strictly correct only for mixtures of non-interacting, ideally sedimenting molecules. It can be applied to interacting molecules if the reaction is slow on the time-scale of sedimentation, or if for other reasons the species are stable during sedimentation (e.g. when working with concentrations much larger than Kd). In any case, however, correct weight-average s-values are obtained from integration of c(s) (in particular, this is true for interacting components).
In this particular model, the parameters s and D required for solving the Lamm equation L(s,D,r,t) for each species are calculated with the approximation that all species in solution have the same weight-average frictional ratio. For each s value, using an estimate of f/f0 and values for the partial-specific volume, buffer density and viscosity, Sedfit estimates the molar mass M(s) and the diffusion coefficient D(s): First the relationships
![]()
(with the frictional coefficient f0 of a smooth compact sphere with radius r in a solvent of viscosity h) and the Svedberg relationship
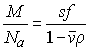
(for a particle of mass M, sedimentation coefficient s, frictional coefficient f and the partial-specific volume n, in a solvent with density r, with Avogadro's number Na) are combined to
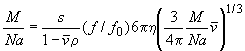
(using the particle mass and partial-specific volume to calculate the radius of the equivalent smooth compact sphere) and resolved to give the molar mass M(s):
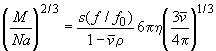
Then, M(s) and s can be re-inserted into the Svedberg equation (in a different form that includes the diffusion coefficient) to give
![]()
With that, we have s and estimate of D(s), which is sufficient to solve the Lamm equation. This model is described in detail in ref 1. The result of the c(s) analysis is a differential sedimentation coefficient distribution, scaled such that the area under the c(s) curve from s1 to s2 will give the loading concentration of macromolecules with sizes between s1 and s2. The whole procedure can also be expressed in a single formula as
![]()
The c(s) distribution is not very sensitive to the parameter f/f0. (Fitting for f/f0 in a nonlinear regression will give an estimate of the weight-average frictional coefficient of all macromolecular species in solution, as shown in the tutorial. Also, when interpreting the parameter f/f0, note that this is an anhydrous frictional ratio, and that it is only a multiplicative factor together with the solvent viscosity.) Therefore, the c(s) distribution is in general a good model for identifying the number of species or characterizing the size-distribution of mixtures of macromolecules. The deconvolution of diffusion gives particular good resolution when applied to discrete mixtures. If there is additional prior knowledge, this should be build into the analysis. Therefore, in addition to the general c(s) model, Sedfit has currently three special cases implemented:
* if there is a main species with known molar mass, the conformational change model is appropriate.
* if all species have the same diffusion coefficient, the continuous c(s) with invariant D should be used.
* if the sedimentation pattern of a low-molecular weight component is superimposed to the signal from faster sedimenting macromolecules, the continuous c(s) with 1 discrete component should be best.
* for calculating a diffusion-deconvoluted sedimentation coefficient distributions without the scaling relationships of frictional ratios, see the c(s,f) and c(s,*) models.
Note: for a generalization of c(s) with other prior knowledge, look at the SedPHaT hybrid continuous/discrete model.
New in version 8.9: SEDPHAT can be spawned automatically in this model with the current data using the Export function.
The general strategy recommended for this model is described in the tutorial on size-distribution. Like with all other direct boundary models, ANY data from the entire sedimentation process can be modeled, and should be included into the analysis for optimal results. There is no need to clear the meniscus, and no need for plateaus or to exclude scans where the boundary is close to the bottom and only partially visible.
For the generic c(s) model assuming similarity of the frictional ratio, the parameters are entered in the parameter input box (Parameters):
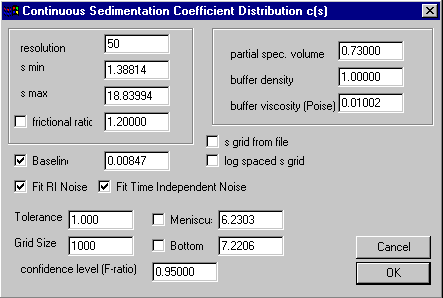
upper section specifying
the distribution range and parameters for the Lamm equation solution
middle section with experimental conditions
lower section with Lamm equation and
nonlinear regression parameters
The parameters are explained in more detail in the introduction to size-distribution analysis. In brief:
The parameters specifying the distribution range and resolution follow the general parameter outline common to all distributions. In brief, s-min and s-max are the smallest and largest s-value of the distribution, and the resolution value determines how many s-values will be used in between. (In c(s) they are spaced equidistant.)
New in version 8.5: There is the option to space the s-values logarithmically, which can be useful if a very large range of s-values has to be covered. Alternatively, a file containing a desired number and spacing of s-values can be read. The filename should be named 'sdist.ip1' (e.g., for scans series *.ip1) and be placed in the directory where the scans are located. Each time a distribution analysis is performed, such a file is automatically created, which can serve as a template for modification.
New in version 8.7: When using the inhomogeneous solvent mode, e.g. to correct for solvent compressibility, please read the specific instructions for this Sedfit mode first. Mainly, this will mean that the s-values are corrected to standard conditions (water 20C), and that the buffer viscosity and density in this input box here also refer to standard conditions.
The frictional ratio value is the weight-average frictional ratio of all species, and if the check-box is marked, this parameter will be optimized when executing a fit command. The partial specific volume, the buffer density, and the buffer viscosity are additional parameters needed to calculate D for each s-value. It should be noted that Sedfit does not use this information to correct the s-values to s20,w. Also, since the frictional ratio and the viscosity are multiplicative, errors in one can be compensated in the other.
The middle section with the parameters for baseline, RI noise, and time-independent noise are the same as in all the other models (explained in detail in the non-interacting discrete species model). Also, the meaning of Tolerance, Grid Size, Meniscus and Bottom is the same as usual.
Important is the confidence level (F-ratio) setting, which determines the magnitude of the regularization. Also, the choice of the regularization method (Tikhonov-Philips 2nd derivative versus maximum entropy) is relevant, as explained in the introduction on the size-distribution analysis. This setting can be changed in the size-distribution options.
After calculating the distribution, a new plot appears in the lower part of the Sedfit window, showing the distribution. Like all distributions, it can be saved to a file (save continuous distribution), copied as graphics metafile (copy distribution plot) or data table (copy distribution table) into the clipboard. As described in the size-distribution tutorial, copying the data into another plotting program is recommended in particular if possible small contribution of species besides the main peaks are of interest. For statistical analysis (provided the fit was good, with evenly distributed residuals), the Monte-Carlo analysis can be performed.
Please note:
Because the inversion of integral equations tends to produce artificial oscillations, great care should be taken in the interpretation of the fine structure of the obtained distributions. Too little regularization can produce such artificial fine-structure. However, this can be assessed by Monte-Carlo analysis.Please note:
The calculation will be aborted if the distribution contains s-values exceeding the maximum s-value that can be observed for the given rotor speed and time of the first scan. To fix this problem, either load earlier data, or reduce the entry in the s-max field appropriately (see message box). It is recommended to stay well below this maximal s-value to avoid artifactual increases of the size-distribution near the maximal value. These issues are explained in the tutorial on size-distribution analysis.Tips:
* If the Lamm equation simulations during this method are very slow, the value for changing the finite element methods should be increased (e.g. to 10).
* In order to achieve smoother distributions, for example when studying synthetic polymers that are known to have a broad distribution, the value of P can be increased, to values close to 1 (e.g. 0.99), or even to 1.1, or better, the regularization should be switched to Tikhonov-Philips regularization.
* The computation time can be reduced by changing the radial resolution.
Reference:
P. Schuck (2000) Size distribution analysis of macromolecules by sedimentation velocity ultracentrifugation and Lamm equation modeling. Biophysical Journal 78:1606-1619